
Adventures in Data Profiling (Part 8)
/Understanding your data is essential to using it effectively and improving its quality – and to achieve these goals, there is simply no substitute for data analysis. This post is the conclusion of a vendor-neutral series on the methodology of data profiling.
Data profiling can help you perform essential analysis such as:
- Provide a reality check for the perceptions and assumptions you may have about the quality of your data
- Verify your data matches the metadata that describes it
- Identify different representations for the absence of data (i.e., NULL and other missing values)
- Identify potential default values
- Identify potential invalid values
- Check data formats for inconsistencies
- Prepare meaningful questions to ask subject matter experts
Data profiling can also help you with many of the other aspects of domain, structural and relational integrity, as well as determining functional dependencies, identifying redundant storage, and other important data architecture considerations.
Adventures in Data Profiling
This series was carefully designed as guided adventures in data profiling in order to provide the necessary framework for demonstrating and discussing the common functionality of data profiling tools and the basic methodology behind using one to perform preliminary data analysis.
In order to narrow the scope of the series, the scenario used was a customer data source for a new data quality initiative had been made available to an external consultant with no prior knowledge of the data or its expected characteristics. Additionally, business requirements had not yet been documented, and subject matter experts were not currently available.
This series did not attempt to cover every possible feature of a data profiling tool or even every possible use of the features that were covered. Both the data profiling tool and data used throughout the series were fictional. The “screen shots” were customized to illustrate concepts and were not modeled after any particular data profiling tool.
This post summarizes the lessons learned throughout the series, and is organized under three primary topics:
- Counts and Percentages
- Values and Formats
- Drill-down Analysis
Counts and Percentages
One of the most basic features of a data profiling tool is the ability to provide counts and percentages for each field that summarize its content characteristics:
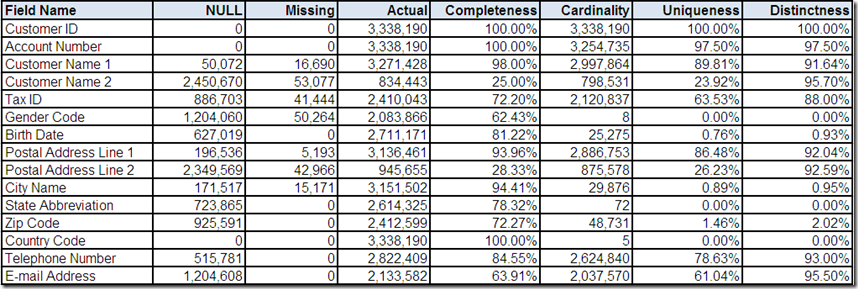
- NULL – count of the number of records with a NULL value
- Missing – count of the number of records with a missing value (i.e., non-NULL absence of data, e.g., character spaces)
- Actual – count of the number of records with an actual value (i.e., non-NULL and non-Missing)
- Completeness – percentage calculated as Actual divided by the total number of records
- Cardinality – count of the number of distinct actual values
- Uniqueness – percentage calculated as Cardinality divided by the total number of records
- Distinctness – percentage calculated as Cardinality divided by Actual
Completeness and uniqueness are particularly useful in evaluating potential key fields and especially a single primary key, which should be both 100% complete and 100% unique. In Part 2, Customer ID provided an excellent example.
Distinctness can be useful in evaluating the potential for duplicate records. In Part 6, Account Number and Tax ID were used as examples. Both fields were less than 100% distinct (i.e., some distinct actual values occurred on more than one record). The implied business meaning of these fields made this an indication of possible duplication.
Data profiling tools generate other summary statistics including: minimum/maximum values, minimum/maximum field sizes, and the number of data types (based on analyzing the values, not the metadata). Throughout the series, several examples were provided, especially in Part 3 during the analysis of Birth Date, Telephone Number and E-mail Address.
Values and Formats
In addition to counts, percentages, and other summary statistics, a data profiling tool generates frequency distributions for the unique values and formats found within the fields of your data source.
A frequency distribution of unique values is useful for:
- Fields with an extremely low cardinality, indicating potential default values (e.g., Country Code in Part 4)
- Fields with a relatively low cardinality (e.g., Gender Code in Part 2)
- Fields with a relatively small number of known valid values (e.g., State Abbreviation in Part 4)
A frequency distribution of unique formats is useful for:
- Fields expected to contain a single data type and/or length (e.g., Customer ID in Part 2)
- Fields with a relatively limited number of known valid formats (e.g., Birth Date in Part 3)
- Fields with free-form values and a high cardinality (e.g., Customer Name 1 and Customer Name 2 in Part 7)
Cardinality can play a major role in deciding whether you want to be shown values or formats since it is much easier to review all of the values when there are not very many of them. Alternatively, the review of high cardinality fields can also be limited to the most frequently occurring values, as we saw throughout the series (e.g., Telephone Number in Part 3).
Some fields can also be analyzed using partial values (e.g., in Part 3, Birth Year was extracted from Birth Date) or a combination of values and formats (e.g., in Part 6, Account Number had an alpha prefix followed by all numbers).
Free-form fields are often easier to analyze as formats constructed by parsing and classifying the individual values within the field. This analysis technique is often necessary since not only is the cardinality of free-form fields usually very high, but they also tend to have a very high distinctness (i.e., the exact same field value rarely occurs on more than one record).
Additionally, the most frequently occurring formats for free-form fields will often collectively account for a large percentage of the records with an actual value in the field. Examples of free-form field analysis were the focal points of Part 5 and Part 7.
We also saw examples of how valid values in a valid format can have an invalid context (e.g., in Part 3, Birth Date values set in the future), as well as how valid field formats can conceal invalid field values (e.g., Telephone Number in Part 3).
Part 3 also provided examples (in both Telephone Number and E-mail Address) of how you should not mistake completeness (which as a data profiling statistic indicates a field is populated with an actual value) for an indication the field is complete in the sense that its value contains all of the sub-values required to be considered valid.
Drill-down Analysis
A data profiling tool will also provide the capability to drill-down on its statistical summaries and frequency distributions in order to perform a more detailed review of records of interest. Drill-down analysis will often provide useful data examples to share with subject matter experts.
Performing a preliminary analysis on your data prior to engaging in these discussions better facilitates meaningful dialogue because real-world data examples better illustrate actual data usage. As stated earlier, understanding your data is essential to using it effectively and improving its quality.
Various examples of drill-down analysis were used throughout the series. However, drilling all the way down to the record level was shown in Part 2 (Gender Code), Part 4 (City Name), and Part 6 (Account Number and Tax ID).
Conclusion
Fundamentally, this series posed the following question: What can just your analysis of data tell you about it?
Data profiling is typically one of the first tasks performed on a data quality initiative. I am often told to delay data profiling until business requirements are documented and subject matter experts are available to answer my questions.
I always disagree – and begin data profiling as soon as possible.
I can do a better job of evaluating business requirements and preparing for meetings with subject matter experts after I have spent some time looking at data from a starting point of blissful ignorance and curiosity.
Ultimately, I believe the goal of data profiling is not to find answers, but instead, to discover the right questions.
Discovering the right questions is a critical prerequisite for effectively discussing data usage, relevancy, standards, and the metrics for measuring and improving quality. All of which are necessary in order to progress from just profiling your data, to performing a full data quality assessment (which I will cover in a future series on this blog).
A data profiling tool can help you by automating some of the grunt work needed to begin your analysis. However, it is important to remember that the analysis itself can not be automated – you need to review the statistical summaries and frequency distributions generated by the data profiling tool and more important – translate your analysis into meaningful reports and questions to share with the rest of your team.
Always remember that well performed data profiling is both a highly interactive and a very iterative process.
Thank You
I want to thank you for providing your feedback throughout this series.
As my fellow Data Gazers, you provided excellent insights and suggestions via your comments.
The primary reason I published this series on my blog, as opposed to simply writing a whitepaper or a presentation, was because I knew our discussions would greatly improve the material.
I hope this series proves to be a useful resource for your actual adventures in data profiling.
The Complete Series
- Adventures in Data Profiling (Part 1) – Series Introduction
- Adventures in Data Profiling (Part 2) – Customer ID and Gender Code
- Adventures in Data Profiling (Part 3) – Birth Date, Telephone Number and E-mail Address
- Adventures in Data Profiling (Part 4) – City Name, State Abbreviation, Zip Code and Country Code
- Adventures in Data Profiling (Part 5) – Postal Address Line 1 and Postal Address Line 2
- Adventures in Data Profiling (Part 6) – Account Number and Tax ID
- Adventures in Data Profiling (Part 7) – Customer Name 1 and Customer Name 2

