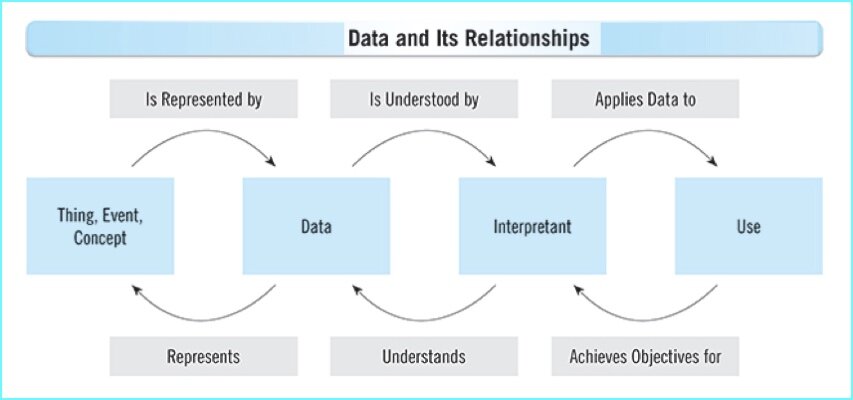
Data Quality and the OK Plateau
/In his book Moonwalking with Einstein: The Art and Science of Remembering, Joshua Foer explained that “when people first learn to use a keyboard, they improve very quickly from sloppy single-finger pecking to careful two-handed typing, until eventually the fingers move so effortlessly across the keys that the whole process becomes unconscious and the fingers seem to take on a mind of their own.”
“At this point,” Foer continued, “most people’s typing skills stop progressing. They reach a plateau. If you think about it, it’s a strange phenomenon. After all, we’ve always been told that practice makes perfect, and many people sit behind a keyboard for at least several hours a day in essence practicing their typing. Why don’t they just keep getting better and better?”
Foer then recounted research performed in the 1960s by the psychologists Paul Fitts and Michael Posner, which described the three stages that everyone goes through when acquiring a new skill:
- Cognitive — During this stage, you intellectualize the task and discover new strategies to accomplish it more proficiently.
- Associative — During this stage, you concentrate less, make fewer major errors, and generally become more efficient.
- Autonomous — During this stage, you have gotten as good as you need to get, and are basically running on autopilot.
“During that autonomous stage,” Foer explained, “you lose conscious control over what you are doing. Most of the time that’s a good thing. Your mind has one less thing to worry about. In fact, the autonomous stage seems to be one of those handy features that evolution worked out for our benefit. The less you have to focus on the repetitive tasks of everyday life, the more you can concentrate on the stuff that really matters, the stuff you haven’t seen before. And so, once we’re just good enough at typing, we move it to the back of our mind’s filing cabinet and stop paying it any attention.”
“You can see this shift take place in fMRI scans of people learning new skills. As a task becomes automated, parts of the brain involved in conscious reasoning become less active and other parts of the brain take over. You could call it the OK plateau, the point at which you decide you’re OK with how good you are at something, turn on autopilot, and stop improving.”
“We all reach OK plateaus in most things we do,” Foer concluded. “We learn how to drive when we’re in our teens and once we’re good enough to avoid tickets and major accidents, we get only incrementally better. My father has been playing golf for forty years, and he’s still a duffer. In four decades his handicap hasn’t fallen even a point. Why? He reached an OK plateau.”
I believe that data quality improvement initiatives also eventually reach an OK Plateau, a point just short of data perfection, where the diminishing returns of chasing after zero defects gives way to calling data quality as good as it needs to get.
As long as the autopilot is on, accepting data quality is a journey not a destination, preventing data quality from getting worse, and making sure best practices don’t stop being practiced, then I’m OK with data quality and the OK plateau. Are you OK?
Related Posts
|
The Dichotomy Paradox, Data Quality and Zero Defects |
The Seventh Law of Data Quality |