Adventures in Data Profiling (Part 3)
/In Part 2 of this series: The adventures continued with a detailed analysis of the Customer ID field and the preliminary analysis of the Gender Code and Customer Name fields. This provided you with an opportunity to become familiar with the features of the fictional data profiling tool that you are using throughout this series to assist with performing your analysis.
Additionally, some of your fellow Data Gazers have provided excellent insights and suggestions via the comments they have left, including my time traveling alter ego who has left you some clues from what the future might hold when you reach the end of these adventures in data profiling.
In Part 3, you will continue your adventures by using a combination of field values and field formats to begin your analysis of the following fields: Birth Date, Telephone Number and E-mail Address.
Birth Date
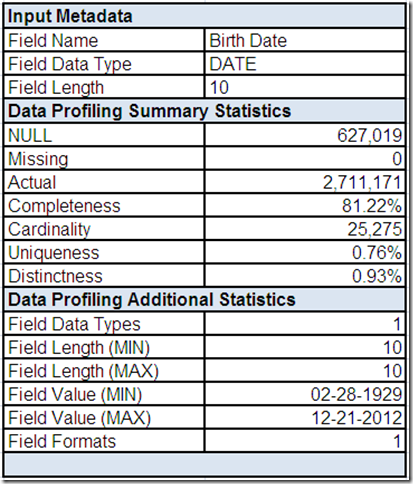
The field summary for Birth Date includes input metadata along with the summary and additional statistics provided by the data profiling tool. Let's assume that drill-downs revealed the single profiled field data type was DATE and the single profiled field format was MM-DD-CCYY (i.e. Month-Day-Year).
Combined with the profiled minimum/maximum field lengths and minimum/maximum field values, the good news appears to be that when Birth Date is populated it does contain a date value.
However, the not so good news is that the profiled maximum field value (December 21, 2012) appears to indicate that some of the customers are either time travelers or the marketing department has a divinely inspired prospect list.
This is a good example of a common data quality challenge – a field value can have a valid data type and a valid format – but an invalid context. Although 12-21-2012 is a valid date in a valid format, in the context of a birth date, it can't be valid.
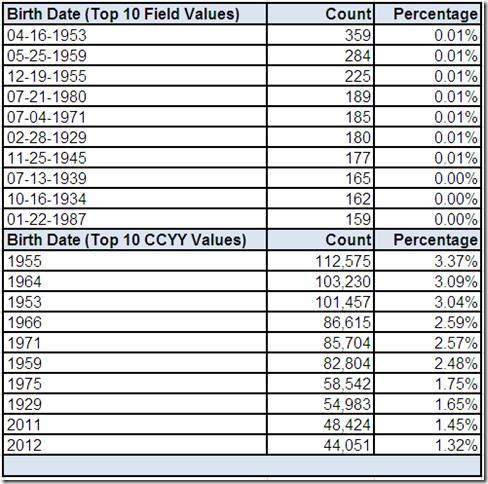
We can use drill-downs on the field summary “screen” to get more details about Birth Date provided by the data profiling tool.
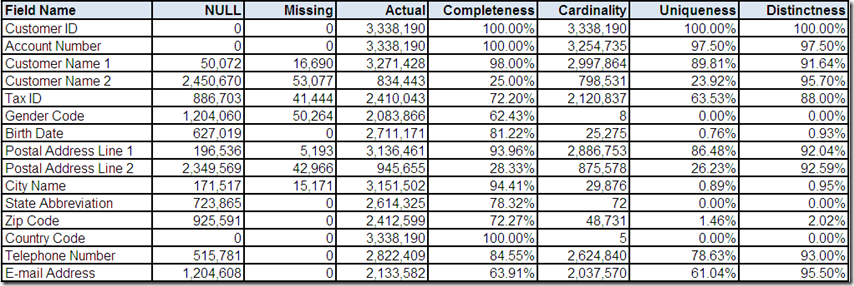
The cardinality of Birth Date is not only relatively high, but it also has a very low Distinctness (i.e. the same field value frequently occurs on more than one record). Therefore, we will limit the review to only the top ten most frequently occurring values.
Additional analysis can be performed by extracting the birth year and reviewing only its top ten most frequently occurring values. One aspect of this analysis is that it can be used as an easier method for examining the customer age range.
Here we also see two contextually invalid birth years: 2011 and 2012. Any thoughts on a possible explanation for this data anomaly?
Telephone Number
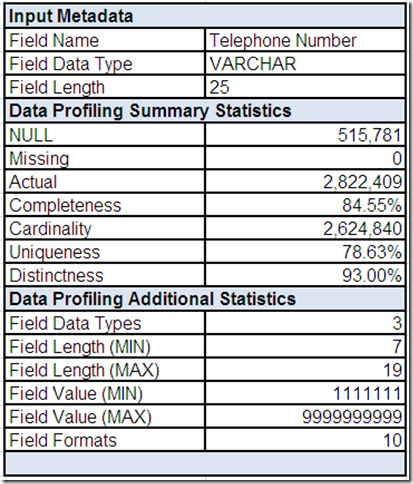
The field summary for Telephone Number includes input metadata along with the summary and additional statistics provided by the data profiling tool.
The presence of both multiple profiled field data types and multiple profiled field formats would appear to indicate inconsistencies in the way that telephone numbers are represented.
The profiled minimum/maximum field lengths show additional inconsistencies, but perhaps more concerning is the profiled minimum/maximum field values, which show obviously invalid telephone numbers.
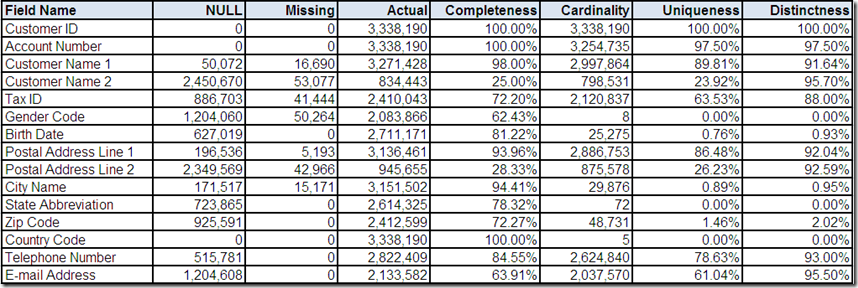
Telephone Number is a good example of how you should not mistake Completeness (which as a data profiling statistic indicates the field is populated with an Actual value) for an indication that the field is complete in the sense that its value contains all of the sub-values required to be considered valid.
This summary information points to the need to use drill-downs in order to review more detailed information.
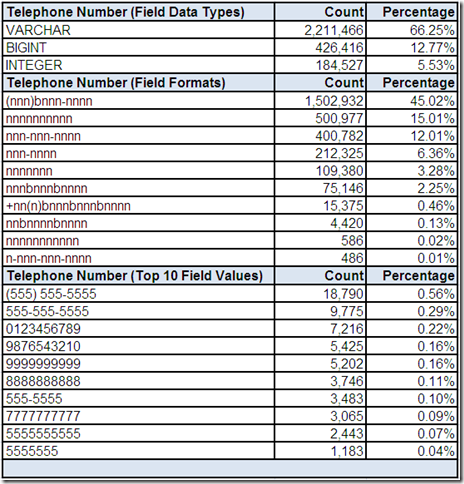
The count of the number of distinct data types is explained by the data profiling tool observing field values that could be represented by three different data types based on content and numeric precision.
With only ten profiled field formats, we can easily review them all. Most formats appear to be representative of potentially valid telephone numbers. However, there are two formats for 7 digit numbers appearing to indicate local dialing syntax (i.e. missing the area code in the United States). Additionally, there are two formats that appear invalid based on North American standards.
However, a common data quality challenge is that valid field formats can conceal invalid field values.
Since the cardinality of Telephone Number is very high, we will limit the review to only the top ten most frequently occurring values. In this case, more obviously invalid telephone numbers are discovered.
E-mail Address
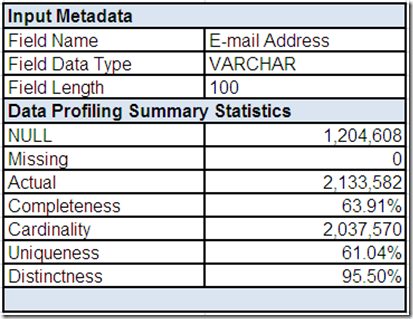
The field summary for E-mail Address includes input metadata along with the summary statistics provided by the data profiling tool. In order to save some space, I have intentionally omitted the additional profiling statistics for this field.
E-mail Address represents a greater challenge that really requires more than just summary statistics in order to perform effective analysis.
Most data profiling tools will provide the capability to analyze fields using formats that are constructed by parsing and classifying the individual values within the field.
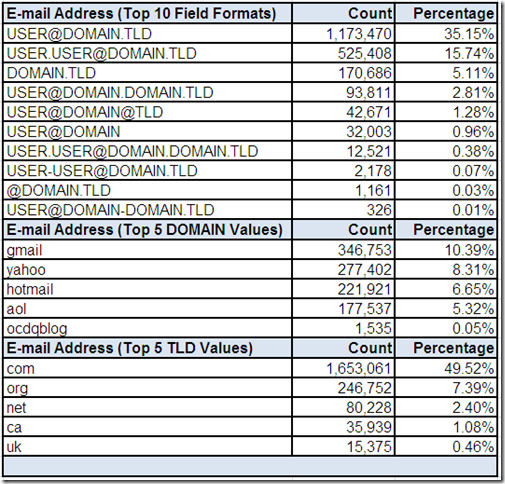
In the case of the E-mail Address field, potentially valid field values should be comprised of the sub-values User, Domain and Top Level Domain (TLD). These sub-values also have expected delimiters such as User and Domain being separated by an at symbol (@) and Domain and TLD being separated by a dot symbol(.).
Reviewing the top ten most frequently occurring field formats shows several common potentially valid structures. However, some formats are missing one of the three required sub-values. The formats missing User could be an indication that the field sometimes contains a Website Address.
Extracting the top five most frequently occurring Domain and TLD sub-values provides additional alternative analysis for a high cardinality field.
What other questions can you think of for these fields? Additional analysis could be done using drill-downs to perform a more detailed review of records of interest. What other analysis do you think should be performed for these fields?
In Part 4 of this series: We will continue the adventures by shifting our focus to postal address by first analyzing the following fields: City Name, State Abbreviation, Zip Code and Country Code.
Related Posts
Adventures in Data Profiling (Part 1)
Adventures in Data Profiling (Part 2)
Adventures in Data Profiling (Part 4)
Adventures in Data Profiling (Part 5)
Adventures in Data Profiling (Part 6)
Adventures in Data Profiling (Part 7)